

DE SUPPLY CHAIN BLOG
Locaties van distributiecentra verschuiven naar stedelijke gebieden
Bij het kiezen van de locaties van je DC's is het belangrijk om te letten op de trends in e-commerce en de noodzaak om te leveren aan klanten in grootstedelijke markten.
Bij het kiezen van de locaties van je DC's is het belangrijk om te letten op de trends in e-commerce en de noodzaak om te leveren aan klanten in grootstedelijke markten.
De bouw van Fulfillment Centers gaat door, maar de focus ligt nu op grote stedelijke markten, niet op goedkope, minder ontwikkelde gebieden
SCDigest besprak observaties van Amazons netwerkstrategie en hoe die evolueert. Ze tonen een diagram van MWPVL dat laat zien dathet bestaande netwerk (blauwe stippen) zich grotendeels in meer landelijke gebieden bevond, of in ieder geval niet erg stedelijk - regio's waar de grond- en arbeidskosten lager waren. De faciliteiten in aanbouw bevinden zichnu echter over het algemeen in stedelijke gebieden - de regio New York City, Chicago, Philadelphia, etc., zoals te zien is in de grotere rode stippen.

Amazon is nu op zoek naar een snelle orderdoorlooptijd (d.w.z. dezelfde dag) voor alle grote steden in de VS. Dit is een andere benadering dan in het verleden, toen de nadruk meer op de kosten lag.
Bron: http://www.scdigest.com/assets/newsviews/14-06-04-1.php?cid=8152
Amazon's uitbreiding van magazijnen gaat onverminderd door als middel voor onbetwiste dominantie
Amazon werkt aan steeds snellere leveringen van online bestellingen - waaronder verzendingen op dezelfde dag - bij het winkelend publiek thuis. Dit betekent dat ze meer distributiecentra in stedelijke gebieden nodig hebben.
Consumenten verwachten nu een tijdige levering binnen twee tot drie dagen. Dit is slechts de minimale verwachting. De trend verschuift van verzending vanuit een specifiek magazijn naar een dichterbij gelegen magazijn om klanten te bedienen, met snellere levering en goedkopere transportkosten.
Supply Chain Analytics en sociale-mediagegevens
Supply Chain Analytics zou ook Social Analytics moeten omvatten, omdat het bekijken van sociale gegevens supply chain managers kan helpen belangrijke aanpassingen te maken, de juiste voorraadniveaus te handhaven, orderbeheer te monitoren en retouren te verminderen. Dit zal het bedrijf helpen de kosten tot een minimum te beperken en de klantwaarde te verhogen.
Supply Chain Analytics zou ook Social Analytics moeten omvatten, omdat het bekijken van sociale gegevens supply chain managers kan helpen belangrijke aanpassingen te maken, de juiste voorraadniveaus te handhaven, orderbeheer te monitoren en retouren te verminderen. Dit zal het bedrijf helpen de kosten tot een minimum te beperken en de klantwaarde te verhogen.
Wat betekent sociale media voor uw toeleveringsketen?
Luciano Cunha bespreekt op de Warehouse Management Systems Guide hoe bedrijven kunnen beginnen na te denken over het gebruik van sociale media in de toeleveringsketen. In het bijzonder merkt hij op dat "de absolute real-time aard die inherent is aan sociale media kan fungeren als een zegen en een vloek voor professionals die toezicht houden op een supply chain. In één opzicht kan toegang tot realtime gegevens supply chains helpen om ultra lean te werken - omdat een goede analyse kan leiden tot het produceren van precies genoeg producten om aan de vraag van de consument te voldoen."
Bron: http://www.warehousemanagementsystemsguide.com/blog/social-media-supply-chain-042711/
Beheer uw Supply Chain Analytics als een honkbalteam
Jeff Kavanaugh schreef in Industry Week dat "Social analytics de mogelijkheid heeft om de toeleveringsketen te helpen".
Sociale media en Supply Chain Analytics
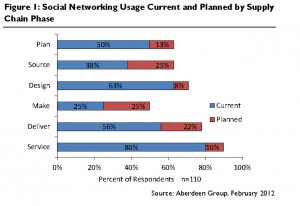
managers kritieke aanpassingen doen, de juiste voorraadniveaus handhaven, orderbeheer bewaken en retouren verminderen, wat op zijn beurt helpt om de kosten te beheersen en de klanttevredenheid te verbeteren."
Bron:http://www.industryweek.com/customer-relationships/manage-your-supply-chain-analytics-baseball-team
Geavanceerde analyse toegepast op supply chain- en handelsgegevens
Hoe houdt een bedrijf rekening met de beschikbare gegevens van sociale media? Marc Dragon besprak in een interview met Dustin Mattison het gebruik van geavanceerde analyses voor gegevens over de toeleveringsketen en de handel. Hij gelooft in het kijken naar drie verschillende soorten gegevensbronnen: de eigen gegevensbron - de gestructureerde gegevens binnen bedrijven, de betaalde gegevensbronnen en de gegevens van sociale media.
Conclusie
Beoefenaars van supply chain analytics kunnen gegevens van sociale media gebruiken in hun analyses. Ze moeten profiteren van de mogelijkheden om gegevens van sociale media te gebruiken voor het verbeteren van voorspellingen en het voldoen aan de vraag. Uiteindelijk gaat social analytics over het gebruik van sociale media om de voorspelbaarheid van belangrijke operationele statistieken te vergroten.
Interview: Waarom is Supply Chain Analytics echt belangrijk?
Hakan Andersson bespreekt waarom Supply Chain Analytics er echt toe doet.
In de volgende video bespreekt Hakan Andersson waarom Supply Chain Analytics er echt toe doet.
Belangrijkste opmerkingen:
De uitdagingen van Big Data
Vier problemen met gegevensanalyse van de toeleveringsketen
Soorten analyse van supply chain-gegevens die moeten worden uitgevoerd
Waarom is het moeilijk om big data te begrijpen?
Allereerst wil ik zeggen dat het geweldig is om big data te hebben. Nu we gegevens hebben, gegevens op een diep niveau, hebben we de computerkracht om de gegevens te verwerken. Dit betekent dat we feitelijk, dicht bij het moment waarop dingen gebeuren, kunnen vaststellen wat de werkelijkheid is. We hoeven niet te vertrouwen op gevestigde waarheden die heel vaak geen waarheden blijken te zijn, maar eerder bedrijfsmythes.
Het risico hier is dat, met al deze prachtige gegevens die beschikbaar zijn, het heel gemakkelijk is om je te laten meeslepen. Er is ook een risico dat de gegevens voor veel mensen beschikbaar zijn. Iedereen die over deze gegevens beschikt, kan zijn eigen conclusies trekken. Daarom moeten de gegevens worden gecureerd; ze moeten worden behandeld door iemand die de expertise en de kennis over de activiteiten heeft. Anders kunnen de conclusies die iedereen met toegang tot de gegevens trekt heel goed fout zijn en ben je appels met ananassen aan het vergelijken.
Uit de Establish-Davis Database, waarin we al bijna veertig jaar de logistieke kosten en diensten volgen, weten we dat je echt moet weten wat vergelijkbaar is en wat niet.
Het is niet eerlijk om de logistieke kosten voor een hoogwaardig artikel met een laag gewicht zoals farmaceutische producten te vergelijken met een bedrijfstak als de staalindustrie, waar artikelen een lage waarde en een hoog gewicht hebben. Dat maakt veel verschil en het kan een probleem vormen als je aan de supply chain kant van het bedrijf staat, want dan ben je de hele tijd in de verdediging en probeer je uit te leggen waarom dingen goed of fout zijn, en je moet de baas zijn over wat belangrijk en goed is.
Moeilijkheden bij de analyse van supply chain-gegevens
Een moeilijkheid bij het sorteren van de gegevens is ten eerste dat de gegevens nooit - ik zeg bijna nooit - schoon zijn. Het feit dat je veel gegevens hebt en het lijkt alsof ze heel nauwkeurig en geldig zijn, betekent niet dat ze dat ook zijn, dus je moet de zwakke punten van de gegevens kennen en identificeren, weten waar de hoofdbestanden zijn bijgewerkt en waar niet en waar je gewoon een plaatshouder hebt en waar het echt materiaal is.
Een ander probleem met schone gegevens is dat zelfs als de gegevens kloppen, ze extremen en uitschieters kunnen bevatten die de resultaten van de analyse die je maakt verstoren. Daarom is het een eerste stap om de gegevens op te schonen, de extremen te identificeren en de zwakke punten te kennen waar je de gegevens kunt gebruiken en waar ze niet geldig zijn.
Je moet beslissen wat belangrijk is. Hier is het gemakkelijk om te verdwalen in een hoop analyse en je moet weten wat echt zinvol is en waar je de output van de analyse vandaan haalt.
Je moet de gegevens vergelijkbaar maken. Je moet ze bijvoorbeeld vergelijkbaar maken in de tijd, zodat je weet wanneer het bedrijf is veranderd, en je moet aanpassingen maken aan de trends. Trendanalyse is de beste manier om te controleren en vast te stellen waar je maatregelen om bijvoorbeeld de efficiëntie te verbeteren hun vruchten afwerpen en waar je beter moet kijken.
Met big data wil je ook benchmarken tussen je entiteiten en extern benchmarken. Dan moet je de gegevens vergelijkbaar maken tussen de entiteiten.
Een voor de hand liggend en misschien klein voorbeeld zijn de faciliteiten. Er zijn kosten verbonden aan het onderbrengen van de inventaris, waarbij je sommige faciliteiten zelf kunt bezitten en andere kunt huren. De werkelijke kosten die je zou moeten gebruiken kunnen hetzelfde zijn, maar de faciliteit in eigendom kan zeer gunstig uitkomen in deze vergelijkingen. Hier zou je een fictieve huur kunnen creëren om het speelveld gelijk te maken.
Welke soorten analyse van supply chain-gegevens moeten worden uitgevoerd en waarom?
Dit hangt natuurlijk af van de behoeften. In welke fase bevindt u zich? Draai je een bedrijf om? Houd je gewoon een goed functionerend bedrijf in de gaten? Zijn er fusies geweest, enzovoort?
Het eerste gebied waar je naar wilt kijken zijn de kosten en de efficiëntie. We zijn geneigd om eerst te kijken naar de logistieke kosten en structuur per artikel, per klant en per leverancier, en we kijken naar de orderstructuur. We proberen te kijken naar wat de kosten veroorzaakt. Door vuistregels of gedetailleerde kennis uit andere analyses toe te passen, kunnen we vaststellen welke artikelen winstgevend zijn, op welke klanten we ons moeten richten, met welke leveranciers we overeenkomsten hebben waardoor de landingskosten hoger zijn dan we dachten.
Als we dit weten, kunnen we strategieën maken voor de manier waarop we met klanten omgaan. Het kan zijn, en dat is vaak het geval, dat we een orderstructuur hebben met veel kleine orders. De afhandelingskosten kunnen hoog zijn voor elke bestelling, dus de kleine bestellingen maken de hele operatie onrendabel. Als we dat weten, kunnen we verschillende manieren vinden om de orderafhandeling te automatiseren of gratis vrachtlimieten of afhandelingskosten te hanteren.
Er zijn veel manieren waarop je deze kennis kunt gebruiken. Als je naar de leveranciers kijkt, zie je vaak dat ze een beetje ongericht zijn, alle kanten op wijzen, je hebt veel kleine leveranciers. En het kan zinvol zijn om iemand te hebben die iets duurder is, maar waar de logistiek heel efficiënt en heel gunstig voor je is.
Als we kijken naar efficiëntie, richten we ons natuurlijk op de verwerkingskosten en de facilitaire kosten, we kijken naar orderpicking, ontvangst, administratie. In dit geval willen we trendanalyses doen; we willen intern benchmarken tussen verschillende entiteiten en verschillende faciliteiten; we willen kijken of er een geografisch gebied of land is dat gunstiger en efficiënter is.
Als we dit op orde hebben, is het heel interessant om een externe benchmark te maken. Waar zijn je concurrenten? Ik heb het al eerder gehad over de Establish-Davis Database, die gratis is zodat je een goed beeld kunt krijgen van hoe je presteert ten opzichte van je concurrenten.
Een specifiek gebied zijn de transportkosten. Dit is een kostenpost die in de meeste bedrijven meestal extern is, wat betekent dat het geld op de onderste regel drukt. Door de zendingen en de behoefte aan modi te analyseren, kun je erachter komen dat je vaak goedkopere modi kunt gebruiken, je kunt potentiële consolidatiegebieden vinden, waarvan we weten dat ze veel geld besparen en, nogmaals, op het resultaat drukken.
Er zijn nu trendanalyses mogelijk die een aantal jaren geleden niet mogelijk waren met bijvoorbeeld het transport. Vroeger was het onmogelijk om echt een gedetailleerde analyse te maken van hoe de werkelijke vrachtfacturering zich verhield tot de afspraken, maar nu is het mogelijk.
Wat we weten is dat een bedrijf gemiddeld 2 tot 4 procent te veel gefactureerd krijgt als je de werkelijke zending vergelijkt met de overeenkomst en om dit constant te controleren en op te volgen zou iets kunnen zijn dat je uitbesteedt, maar het is ook direct beschikbaar in logistieke controletoren transportmanagementsystemen, of je kunt het, in sommige gevallen, zelf doen zonder die analysetools.
Als je kijkt naar een meer strategisch niveau, hebben we het gehad over de analyse van leveranciers, orderstructuur, klanten, artikelen, assortimentanalyse, maar een zeer lucratief gebied om naar te kijken is de distributie-netwerkanalyse. Wat je doet is kijken naar... sla ik de juiste hoeveelheid van elk artikel op om een bepaald serviceniveau te bereiken? Sla ik de artikelen op waar dat qua kosten het gunstigst is? Sla ik ze op waar het het makkelijkst en goedkoopst is om naar klanten te verzenden? Dit is allemaal mogelijk met gegevens die direct beschikbaar zijn.
Conclusie
Samenvattend bieden de supply chain analyses die nu mogelijk zijn een geweldige kans voor jou als supply chain manager om het stuur in handen te krijgen. Dit is een gebied waar het heel kwantificeerbaar is en waar je cijfers op kunt plakken. Als je de gegevens hebt, kun je de leiding nemen, je kunt bepalen wat belangrijk is en je kunt de efficiëntie sturen en bewaken, en je kunt ook een goede klant zijn voor de leveranciers die je helpen.
Hartelijk dank voor de uitnodiging en ik kijk ernaar uit om weer met u te praten.
Data-driven Supply Chain Analytics Tools zijn niet genoeg
Supply Chain Analytics beoefenaars kunnen veel leren van Customer Analytics. De twee domeinen zijn gebaseerd op vergelijkbare bedrijfsfundamenten. Wat we ontdekken is dat data en datagestuurde beslissingstools niet genoeg zijn. De grootste moeilijkheden in Supply Chain of Customer Analytics liggen in de culturele praktijken van organisaties.
Supply Chain Analytics beoefenaars kunnen veel leren van Customer Analytics. De twee domeinen zijn gebaseerd op vergelijkbare bedrijfsfundamenten. Wat we ontdekken is dat data en datagestuurde beslissingstools niet genoeg zijn. De grootste moeilijkheden in Supply Chain of Customer Analytics liggen in de culturele praktijken van organisaties.
Het volgende artikel is geschreven door Maz Iqbal die zijn waardevolle perspectief vanuit Customer Analytics heeft gegeven.
Op LinkedIn deelt Don Peppers zijn visie op het nemen van betere beslissingen met gegevens. Dit heeft me aan het denken gezet en ik wil met jullie delen wat er bij mij naar boven kwam. Waarom naar mijn verhaal luisteren? Ik heb een wetenschappelijke achtergrond (BSc Toegepaste Natuurkunde). Ik ben gekwalificeerd als registeraccountant en was betrokken bij het produceren van allerlei rapporten voor managers en zag wat ze er wel of niet mee deden. Meer recentelijk was ik hoofd van een datamining en predictive analytics praktijk. Laten we beginnen.
Gegevens en tools voor gegevensgestuurde besluitvorming zijn niet genoeg
Ja, er is een stortvloed aan gegevens en deze stortvloed wordt steeds groter en sneller. Groot en snel genoeg om de pakkende naam Big Data te krijgen. Wat vergeten wordt, is de moeite die het kost om deze gegevens geschikt te maken voor modellering. Dit is geen gemakkelijke en goedkope taak. Toch is het mogelijk als je er genoeg middelen tegenaan gooit.
Ja, er zijn allerlei hulpmiddelen om patronen te vinden in deze gegevens. En in de handen van de juiste mensen (statistisch geschoold, zakelijk onderlegd) kunnen deze tools worden gebruikt om gegevens om te zetten in waardevolle (bruikbare) inzichten.
Dit is niet zo gemakkelijk als het klinkt. Waarom? Omdat er een tekort is aan deze statistisch geschoolde en weldenkende mensen: amateurs volstaan niet, er zijn experts nodig om onderscheid te maken tussen goud en dwaas goud - als je genoeg gegevens hebt, kun je zowat elk patroon vinden. Statistische kennis is niet genoeg, je moet het koppelen aan zakelijk inzicht. Laten we echter aannemen dat we deze beperking kunnen overwinnen.
De echte uitdaging bij het genereren van datagestuurde besluitvorming in bedrijven zijn de culturele praktijken. We hebben niet de culturele praktijken die de ruimte creëren voor datagedreven besluitvorming om te verschijnen en te bloeien. Een denker die veel slimmer is dan ik heeft zijn wijsheid al gedeeld, ik nodig je uit om te luisteren:
"Over het geheel genomen zijn wetenschappelijke methoden minstens zo belangrijk als elk ander onderzoek: want het is van het inzicht in de methode dat de wetenschappelijke geest afhangt: en als deze methoden verloren gaan, dan kunnen alle resultaten van de wetenschap een hernieuwde triomf van bijgeloof en onzin niet voorkomen. Slimme mensen kunnen zoveel leren als ze willen over de resultaten van de wetenschap - toch zal men altijd merken in hun conversatie, en vooral in hun hypotheses, dat ze de wetenschappelijke geest missen; ze hebben niet het kenmerkende wantrouwen tegen de dwalingen van het denken die door lange training diep geworteld zijn in de ziel van elke wetenschappelijke persoon. Ze zijn tevreden met het vinden van welke hypothese dan ook over een bepaalde zaak; dan zijn ze er helemaal klaar voor en denken dat dat genoeg is ........ Als iets onverklaard is, worden ze heet van de naald bij het eerste het beste idee dat in hun hoofd opkomt en op een verklaring lijkt....".
- Nietzsche (Menselijk, al te menselijk)
Het komt bij me op dat de wetenschappelijke methode nooit zijn weg heeft gevonden in het organisatieleven. Zet de rationalistische ideologie opzij en kijk eens goed naar wat er in het bedrijfsleven gebeurt, inclusief hoe beslissingen worden genomen. Ik zeg je dat Nietzsche's doordringende inzicht in de menselijke conditie vandaag de dag nog net zo waar is als toen hij het uitsprak. De praktijk van het nemen van beslissingen in elke organisatie waarmee ik ooit in contact ben gekomen is niet wetenschappelijk: het volgt niet de wetenschappelijke methode.
Integendeel, managers nemen beslissingen die in lijn liggen met hun intuïtie, hun vooroordelen en hun eigenbelang. Het is zo zeldzaam om een manager (en organisatie) tegen te komen die beslissingen neemt op basis van de wetenschappelijke methode, dat als dit gebeurt ik met mijn mond vol tanden sta. Het is net zo onverwacht als wanneer je een vrouwelijke streaker over het voetbalveld ziet rennen tijdens een competitiewedstrijd.
Wat zijn de uitdagingen bij het invoeren van datagestuurde besluitvormingspraktijken in organisaties?
Technologen hebben een gave. Welke gave? De gave dat ze het wezen van de mens niet diep genoeg begrijpen. Omdat ze dit niet begrijpen, kunnen ze (vol vertrouwen) opstaan en de deugden en voordelen van technologie prediken. Als het leven zo eenvoudig was.
De waarheid klinkt aantrekkelijk voor degenen onder ons die de gevolgen van de waarheid niet onder ogen hoeven te zien. Datagestuurde besluitvorming klinkt geweldig voor degenen onder ons die datagestuurde tools en diensten verkopen (er geld mee verdienen en hopen rijk te worden).
De uitdaging van het invoeren van datagestuurde besluitvormingspraktijken is dat het de status-quo verstoort. Wanneer je de status quo verstoort, neem je het op tegen de machtigen die profiteren van die status quo. Denk aan Socrates:
"De aard van wat Socrates deed maakte hem tot een ontwrichtende en subversieve invloed. Hij leerde mensen om alles in vraag te stellen en hij stelde de onwetendheid van individuen met macht en autoriteit aan de kaak. Hij werd geliefd maar ook gehaat .... Uiteindelijk arresteerden de autoriteiten hem voor .... en het niet geloven in de goden van de stad. Hij werd berecht en ter dood veroordeeld...".
- Bryan Magee, hoogleraar
Pas op voor succes bij het invoeren van een cultuur van gegevensgestuurde besluitvorming!
Met voldoende inzet en investeringen kun je een cultuur van datagestuurde besluitvorming creëren. Zoals de mensen bij Tesco hebben gedaan. En door beslissingen te nemen op basis van de gegevens over je klanten, je winkels, je producten, kun je al je concurrenten overtreffen, als een gek groeien en bumperwinsten maken. Opnieuw, opnieuw en opnieuw. Dan komt de dag van de afrekening - wanneer je oog in oog komt te staan met de gebreken van het nemen van beslissingen uitsluitend op basis van gegevens.
Tesco doet het niet zo geweldig. Het gaat al een aantal jaren niet zo goed - in 2012 gaf het bedrijf zelfs voor het eerst een winstwaarschuwing. Wat is de laatste stand van zaken? Tesco heeft een winstdaling van 23,5% gemeld in de eerste helft van dit jaar. Wat heeft Tesco gedaan om de situatie het hoofd te bieden? Dit staat er in het artikel:
Vorig jaar kondigde Tesco aan £1 miljard uit te geven om de winkels in het Verenigd Koninkrijk te verbeteren, door te investeren in winkelupgrades, productassortimenten, meer personeel en het online aanbod.
Datagestuurde besluitvorming heeft een aantal tekortkomingen. Ten eerste gaat datagestuurde besluitvorming ervan uit dat de toekomst een voortzetting zal zijn van het verleden. Dat is net zoiets als zeggen dat alle zwanen die we zijn tegengekomen wit zijn, dus moeten we plannen maken voor witte zwanen. En dan ontdek je op een dag dat de zwarte zwaan opduikt! De recessie en de verschuiving in het consumentengedrag als gevolg van deze recessie was de zwarte zwaan voor Tesco.
Bovendien gok ik dat de mensen bij Tesco in hun aanbidding op de preekstoel van datagestuurde besluitvorming de dimensies zijn vergeten die er wel toe doen, maar die niet zijn ingevoerd in de gegevens en de voorspellende modellen. Welke dimensies? Zoals de winkelervaring van de klant bij Tesco: te weinig personeel, ontevreden personeel, winkels die er met de dag gedateerder uitzien, de kwaliteit van hun producten...
Het lijkt erop dat de mensen bij Tesco geen acht hebben geslagen op de wijze woorden van een van mijn idolen:
Niet alles wat telt kan geteld worden, en niet alles wat geteld kan worden telt.
- Einstein
Dit artikel over 'Musings on Big Data, Customer Analytics, and Data Driven Business' is geschreven door Maz Iqbal, een expert die zich inzet om leidinggevenden, teams en organisaties te helpen het goed te doen door superieure waarde voor klanten te creëren en het leven van alle belanghebbenden te verrijken. Zijn website is http://thecustomerblog.co.uk/